Redis学习笔记

redis 只支持 linux 操作系统
安装
手动编译
1 | wget http://download.redis.io/releases/redis-6.2.6.tar.gz |
配置文件位于 /usr/local/src/redis-6.2.6/redis.conf, 修改配置文件中的 daemonize:yes 使 redis 在后台运行
通过 redis-cli 打开命令行工具
1 | redis-cli [options] [commonds] |
options 可以为
-h 127.0.0.1:指定要连接的 redis 节点的 IP 地址,默认是 127.0.0.1-p 6379:指定要连接的 redis 节点的端口,默认是 6379-a 132537:指定 redis 的访问密码
commands 可以为
ping:与 redis 服务端做测试,服务端正常会返回pong- 不指定 commond 时,会进入
redis-cli的交互控制台:
默认有 16 个数据库,初始使用 0 号库
Redis 是单线程 + 多路 IO 复用
数据类型
5 种基本类型
| 类型名 | 例子 |
|---|---|
| String | hello world |
| Hash | {name : “zhangsan”, age : 18} |
| List | {A -> B -> C -> C} |
| Set | {A, B, C} |
| SortedSet | {A : 1, B : 2, C : 3} |
3 种特殊类型
| 类型名 | 例子 |
|---|---|
| GEO | {A: (120.3, 30.5)} |
| BitMap | 0110110101110101011 |
| HyperLog | 0110110101110101011 |
操作
通用操作
| 指令 | 描述 |
|---|---|
| KEYS | 查看符合模板的所有 key,不建议在生产环境设备上使用 |
| DEL | 删除一个或多个指定的 key |
| EXISTS | 判断 key 是否存在,存在返回 1,不存在返回 0 |
| EXPIRE | 给一个 key 设置有效期,到期时该 key 会被自动删除 |
| TTL | 查看一个 KEY 的剩余有效期,-1 表示永不过期,-2 表示已过期被删除 |
| TYPE | 根据 key 查看数据类型 |
| UNLINK | 非阻塞删除(先将 key 从 keyspace 元数据中删除,真正的删除操作在后续异步执行) |
| DBSIZE | 查看当前数据库的 key 数量 |
String
value 是字符串,根据字符串的格式不同,底层编码方式不同,又可以分为:
string:普通字符串int:整数类型,可以做自增、自减操作float:浮点类型,可以做自增、自减操作
底层为动态扩容大小的字符串,每次扩 1M,最大为 512M。
redis 的操作是原子性的,即不会被打断。
Redis 的 key 允许有多个单词形成层级结构,多个单词之间用 : 隔开,格式如下:项目名:业务名:类型:key
| 命令 | 描述 |
|---|---|
| SET | 添加或者修改已经存在的一个 String 类型的键值对 |
| GET | 根据 key 获取 String 类型的 value |
| MSET | 批量添加多个 String 类型的键值对 |
| MGET | 根据多个 key 获取对应的 String 类型的 value |
| INCR | 让一个整型的 key 自增 1 |
| INCRBY | 让一个整型的 key 自增并指定步长,例如:incrby num 2,让 num 值自增 2 |
| INCRBYFLOAT | 让一个浮点类型的数字自增并指定步长 |
| SETNX | 如果某个 key 不存在,则添加一个 String 类型的键值对,否则不添加 |
| SETEX | 添加一个 String 类型的键值对,并且指定有效期 |
set <key> <value>:添加或修改键值对get <key>:获取相应的 valueappend <key> <value>:将给定的 value 添加到原值的后面并返回新值的长度strlen <key>:获取值的长度setnx <key> <value>:当 key 不存在时,设置对应的值incr <key>:自增decr <key>:自减incrby <key> <step>:指定步长decrby <key> <step>:指定步长
mset <key1> <value1> <key2> <value2>...:批量添加或修改键值对mget <key1> <key2>...:获取相应的 valuemsetnx <key1> <value1> <key2> <value2>...:若有一个设置失败,则整条命令全部失败
getrange <key> <start> <end>:获取 [start, end] 的子串setrange <key> <start> <value>:用 value 从 start 处覆写
setex <key> <exptime> <value>:设置键值对的同时,设置过期时间
getset <key> <value>:获取旧值,同时设置为新值
Hash
| 命令 | 描述 |
|---|---|
| HSET key field value | 添加或者修改 hash 类型 key 的 field 的值 |
| HGET key field | 获取一个 hash 类型 key 的 field 的值 |
| HMSET | hmset 和 hset 效果相同 ,4.0 之后 hmset 可以弃用了 |
| HMGET | 批量获取多个 hash 类型 key 的 field 的值 |
| HGETALL | 获取一个 hash 类型的 key 中的所有的 field 和 value |
| HKEYS | 获取一个 hash 类型的 key 中的所有的 field |
| HVALS | 获取一个 hash 类型的 key 中的所有的 value |
| HINCRBY | 让一个 hash 类型 key 的字段值自增并指定步长 |
| HSETNX | 添加一个 hash 类型的 key的 field 值,前提是这个 field 不存在,否则不执行 |
List
底层为一个双向循环链表。quicklist,每一个节点为多个空间上相邻的数据组成的一个 ziplist,并将一个个 ziplist 使用双向指针串起来。
左侧为头,右侧为尾。
| 命令 | 描述 |
|---|---|
| LPUSH key element … | 向列表左侧插入一个或多个元素 |
| LPOP key | 移除并返回列表左侧的第一个元素,没有则返回 nil |
| RPUSH key element … | 向列表右侧插入一个或多个元素 |
| RPOP key | 移除并返回列表右侧的第一个元素 |
| LRANGE key start end | 返回一段角标范围内的所有元素,从 1 开始,闭区间 |
| BLPOP 和 BRPOP | 与 LPOP 和 RPOP 类似,只不过在没有元素时进行等待指定时间,而不是直接返回 nil |
lpush/rpush <key1> <key2>...:头插法/尾插法插入数据lpop/rpop <key>:头部/尾部抛出一个值
rpoplpush <key1> <key2>:从 key1 尾部抛出一个值以头插法插入 key2
lindex <key> <index>:获取指定索引元素lrange <key> <start> <end>:获取左起 [start, end] 的数据
llen <key>:获取 list 长度
linsert <key> before <value> <newvalue>:在 value 后插入 newvalue
lrem <key> <n> <value>:从左起删除 n 个数据
lset <key> <index> <value>:将 key 下标为 index 的值替换为 value
Set
| 命令 | 描述 |
|---|---|
| SADD key member … | 向 set 中添加一个或多个元素 |
| SREM key member … | 移除 set 中的指定元素 |
| SCARD key | 返回 set 中元素的个数 |
| SISMEMBER key member | 判断一个元素是否存在于 set 中 |
| SMEMBERS | 获取 set 中的所有元素 |
| SINTER key1 key2 … | 求 key1 与 key2 的交集 |
| SDIFF key1 key2 … | 求 key1 与 key2 的差集 |
| SUNION key1 key2 .. | 求 key1 和 key2 的并集 |
SortedSet
SortedSet 中每一个元素都带有一个 score 属性,基于 score 属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
下列命令默认升序排名,如果要降序则在命令的 Z 后面添加 REV:
| 命令 | 描述 |
|---|---|
| ZADD key score member | 添加一个或多个元素到 sorted set ,如果已经存在则更新其 score 值,注意 score 在前 |
| ZREM key member | 删除 sorted set 中的一个指定元素 |
| ZSCORE key member | 获取 sorted set 中的指定元素的 score 值 |
| ZRANK key member | 获取 sorted set 中的指定元素的排名,从 0 开始,表示最小 |
| ZCARD key | 获取 sorted set 中的元素个数 |
| ZCOUNT key min max | 统计 score 值在给定范围内的所有元素的个数,闭集合 |
| ZINCRBY key increment member | 让 sorted set 中的指定元素自增,步长为指定的 increment 值 |
| ZRANGE key min max | 按照 score 排序后,获取指定排名范围内的元素,闭集合,0 开始 |
| ZRANGEBYSCORE key min max | 按照 score 排序后,获取指定 score 范围内的元素 |
| ZDIFF、ZINTER、ZUNION | 求差集、交集、并集 |
Java 客户端
Jedis
Jedis 是 Redis 的 Java 客户端,专为性能和易用性而设计。线程不安全。
引入 Jedis 相关依赖
1 | <dependency> |
编写测试类
1 | package com.pl; |
JedisPool 避免频繁地创建和销毁连接。
1 | package com.pl; |
SpringDataRedis
SpringData 是 Spring 中数据操作的模块,包含对各种数据库的集成,其中对 Redis 的集成模块就叫做SpringDataRedis。
SpringDataRedis 中提供了 RedisTemplate 工具类,其中封装了各种对 Redis 的操作。并且将不同数据类型的操作 APl 封装到了不同的类型中。
| API | 返回类型 | 作用 |
|---|---|---|
| redisTemplate.opsForValue() | ValueOperations | 操作 String 类型数据 |
| redisTemplate.opsForHash() | HashOperations | 操作 Hash 类型数据 |
| redisTemplate.opsForList() | ListOperations | 操作 List 类型数据 |
| redisTemplate.opsForSet() | SetOperations | 操作 Set 类型数据 |
| redisTemplate.opsForZSet() | ZSetOperations | 操作 SortedSet 类型数据 |
| redisTemplate | 通用的操作 |
引入依赖
1 | <dependency> |
配置信息
1 | spring: |
编写测试类
1 | package com.pl; |
RedisTemplate 可以接收任意 Object 作为值写入 Redis,只不过写入前会把 Object 序列化为字节形式,默认是采用JDK序列化,得到的结果可读性差、内存占用较大。通过自定义 RedisTemplate 序列化的方式来解决。
RedisConfig 配置类
1 |
|
测试
1 |
|
JSON 序列化器会将类的 class 类型写入 Redis,带来额外的内存开销。为了节省内存空间,统一使用 String 序列化器,要求只能存储 String 类型的 key 和 value,手动完成对象的序列化和反序列化。
Spring 默认提供了一个StringRedisTemplate 类,它的 key 和 value 的序列化方式默认就是 String 方式。
1 |
|
底层数据结构
动态字符串 SDS
用来保存单个字符串。
底层结构体定义如下:
1 | struct _attribute_((_packed__))sdshdr8 { |
内存预分配扩容规则:
- 如果新字符串小于 1M,新空间为旧串加新串的长度的 2 倍 + 1(1 用作 \0)
- 如果新字符串大于 1M,新空间为旧串加新串的长度 + 1M + 1(1 用作 \0)
eg:
一个内容为 “he” 的 SDS
| len : 2 | alloc : 2 | flags : 1 | h | e | \0 |
要追加一段字符串 “llo”,旧串加新串的长度为 5,新空间为 5 * 2 + 1 = 11
| len : 5 | alloc : 10 | flags : 1 | h | e | l | l | o | \0 | (空) | (空) | (空) | (空) | (空) |
IntSet
Redis 中 Set 的一种实现方式,基于整数数组实现,长度可变、元素唯一、升序。
底层结构体定义如下:
1 | typedef struct intset { |
当插入的元素超出了当前编码格式的范围,自动升级编码方式,按新的编码方式进行原地扩容(倒序),然后将新元素放入队首或队尾,最后修改 encoding 属性。
Dict
实现 KV 映射,由三部分组成:DictHashTable、DictEntry、Dict:
1 | typedef struct dictht { |
添加 KV 对时,先根据 key 计算出哈希值 h,然后 h & sizemask 计算得到该存储的索引位置。若发生哈希冲突,则用头插法插入链表。
根据负载因子(LoadFactor = user/size)状态,触发哈希表扩容 rehash,扩容后大小为第一个大于 used + 1 的 2^n:
- LoadFactor >= 1 且未执行 BGSAVE 或 BGREWRITEAOF 等后台进程
- LoadFactor > 5,立马执行
每次进行删除操作时,若负载因子 < 0.1,进行哈希表收缩 rehash,收缩后大小为第一个大于 used 的 2^n,且不小于 4。
扩容或收缩导致哈希表的 size 和 sizemask 变化,而 key 的查询与 sizemask 有关。因此必须对哈希表中的每一个 key 重新计算索引,插入新的哈希表,这个过程称为 rehash:
- 计算新 hash 表的 realeSize,值取决于当前要做的是扩容还是收缩:
- 扩容,则新 size 为第一个大于等于 dict.ht[o].used +1 的 2^n
- 收缩,则新 size 为第一个大于等于 dict.ht[0].used 的 2^n(不小于4)
- 按照新的 realeSize 申请内存空间,创建 dictht,并赋值给 dict.ht[1]
- 设置 dict.rehashidx=0,标示开始 rehash
- 每次执行新增、查询、修改、删除操作时,都检查一下 dict.rehashidx 是否大于-1,如果是则将 dict.ht[0].table[rehashidx] 的 entry 链表 rehash 到 dict.ht[1],并将 rehashidx++。直至 dict.ht[0] 的所有数据都 rehash 到 dict.ht[1](渐进式 rehash)
- 将 dict.ht[1] 赋值给 dict.ht[0],给 dict.ht[1] 初始化为空哈希表,释放原来的 dict.ht[0] 的内存
ZipList
压缩列表,保存字符串和整数,可看作连续存储的”双向链表“,但列表的节点间并不是通过指针相连,而是记录上一节点和本节点长度用于计算邻接节点位置,相比指针节省内存空间,若数据过多导致链表过长,会影响性能以及导致申请连续内存效率很低。
结构如下,注意所有存储长度的数值均采用小端字节序存储,即低位字节在前,高位字节在后:
| 本节点总字节数(4 字节) | 从起始地址到 tail 节点的偏移量(4 字节) | entry 个数(2 字节) | head 节点(不定) | tail 节点 | 结束标识:0xff(1 字节) | ||
|---|---|---|---|---|---|---|---|
| zlbytes | zltail | zllen | entry | entry | … | entry | zlend |
entry 的具体结构:
| 前一节点总字节数(1 字节或 5 字节) | 编码属性(1、2 或 5 字节) | 数据(字符串或整数,也可能不存在) |
|---|---|---|
| previous_entry_length | encoding | content |
previous_entry_length:前一节点小于 254 字节,则用一个字节保存;前一节点大于等于 254,用 5 个字节保存,第一个字节为标识 0xfe,后 4 个字节保存长度。可能导致连锁更新问题,即连续多个长度为 250~253 字节之间的 entry 时,新增、或删除一个长度大于等于 254 的 entry,会导致一连串的 entry 的 previous_entry_length 所占空间的变动。
encoding:00、01、10 开头,表示 content 为字符串;11 开头,且欲存储的整数不属于 [1, 12],表示 content 为整数。
| 编码 | 长度 | 意义 |
|---|---|---|
| 00###### | 1 字节 | 字符串长度小于等于 63 字节 |
| 01###### ######## | 2 字节 | 字符串长度小于等于 16383 字节 |
| 10000000 ######## ######## ######## ######## | 5 字节 | 字符串长度小于等于 2^32 - 1 字节 |
| 11000000 | 1 字节 | int16_t(2 字节) |
| 11010000 | 1 字节 | int32_t(4 字节) |
| 11100000 | 1 字节 | int64_t(8 字节) |
| 11110000 | 1 字节 | 24 位有符号整数(3 字节) |
| 11111110 | 1 字节 | 8 位有符号整数(1 字节) |
| 1111####(无 content 部分) | 1 字节 | 数值直接保存在 #### 处,减 1 则为实际值 |
QuickList
节点为 ZipList 串成的真双向链表,每个节点有 pre 指针和 next 指针,可控制 ZipList 大小,且节点可压缩。
结构如下:
1 | typedef struct quicklist { |
1 | typedef struct quicklistNode { |
SkipList
ZipList 和 QuickList 适合对队头队尾进行操作,SkipList 适合对中间元素进行操作。
跳跃表是一个双向有序链表,每个节点都包含 score(用于排序)和 ele(存储 SDS 格式数据),节点按照 score 值排序,score 值一样则按照 ele 字典排序。每个节点都可以包含多层指针,层数是 1 到 32 之间,不同层指针到下一个节点的跨度不同,层级越高,跨度越大,增删改查效率与红黑树基本一致,实现却更简单。
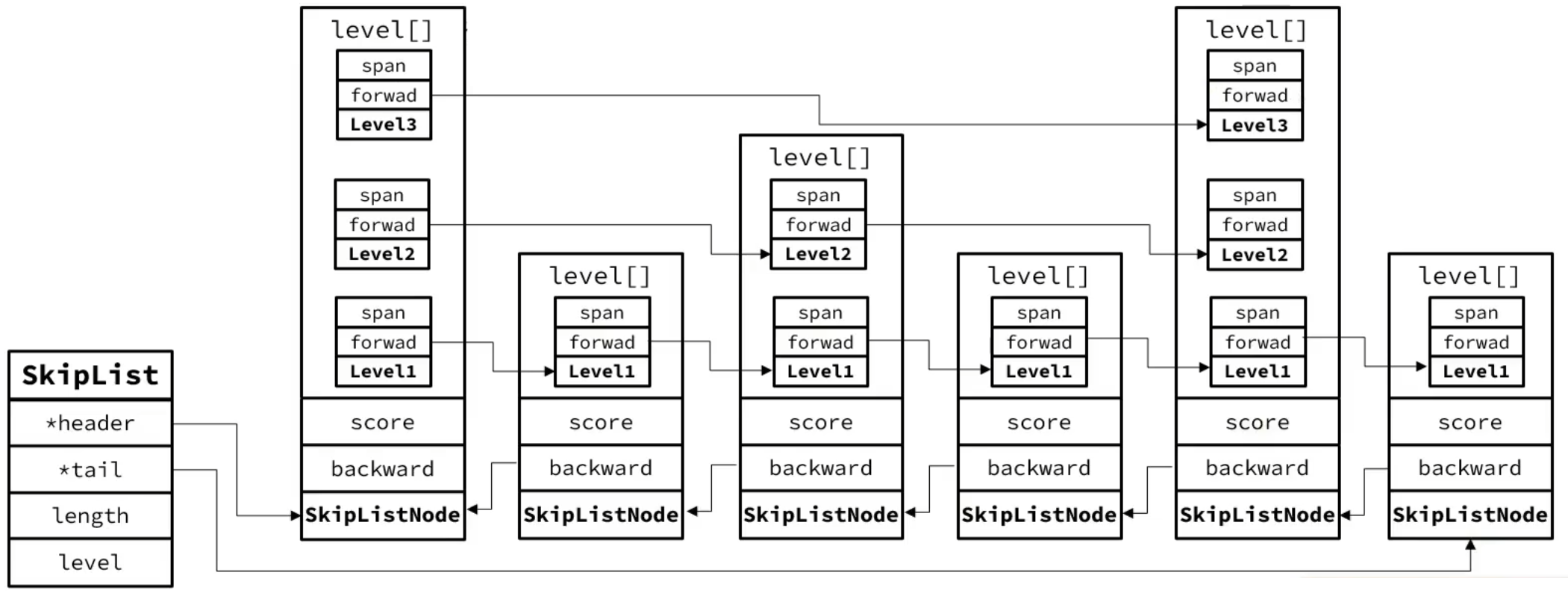
待查找节点的 score 比当前节点 socre 大,则顺着当前等级的指针往后,否则,进入更深一层的指针。
RedisObject
Redis 中任意数据类的 Key 和 Value 都被封装为一个 RedisObject,格式如下:
1 | typedef struct redisObject { |
数据类型和编码方式对象关系如下:
| 数据类型 | 编码方式 |
|---|---|
| OBJ_STRING | raw(SDS 实现,ptr 指向 SDS) 、embstr(SDS 长度小于 44 字节,SDS 紧跟于 ptr 顺序后面,内存中连续存储)、int(long 类型的整数的字符串,ptr 中存数据) |
| OBJ_LIST | v3.2 前:LinkedList、ZipList;v3.2 后:QuickList |
| OBJ_SET | Intset(数据都是整数且数量不超过 set-max-intset-entries 时,默认 512)、HT |
| OBJ_ZSET | ZipList(元素数量不超过 zset_max_ziplist_entries,默认 128 且 元素都小于 zset_max_ziplist_value,默认 64,score 和 element 作为连续的两个 entry) HT(实现唯一性、根据 member 查 score) 和 SkipList(实现有序性) |
| OBJ_HASH | ZipList、HT |



